
 Kimi K3
Kimi K3OpenAI-формат
Описание
OpenAI-формат взаимодействия с LLM через GenAPI доступен по специальному поддомену, отличному от основного:
https://proxy.gen-api.ru
На нём доступен основной эндпоинт /v1
POST
https://proxy.gen-api.ru/v1
Авторизация
Авторизация запросов производится с помощью Bearer токена (вашего API-ключа, созданного на сайте GenAPI) абсолютно аналогично, как и для всего остального нашего функционала. Подробно описано в разделе Авторизация.
Выбор модели
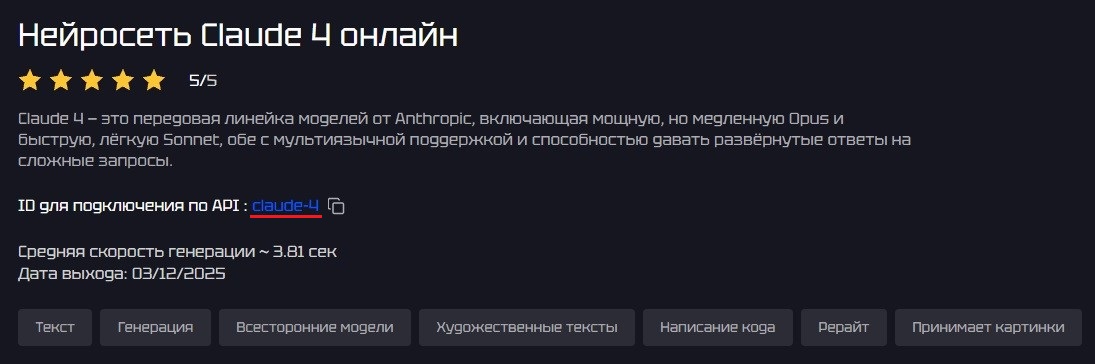
Указание конкретной модели, к которой идёт запрос, осуществляется через параметр model. Параметр model берётся из id нейросети.
Важно
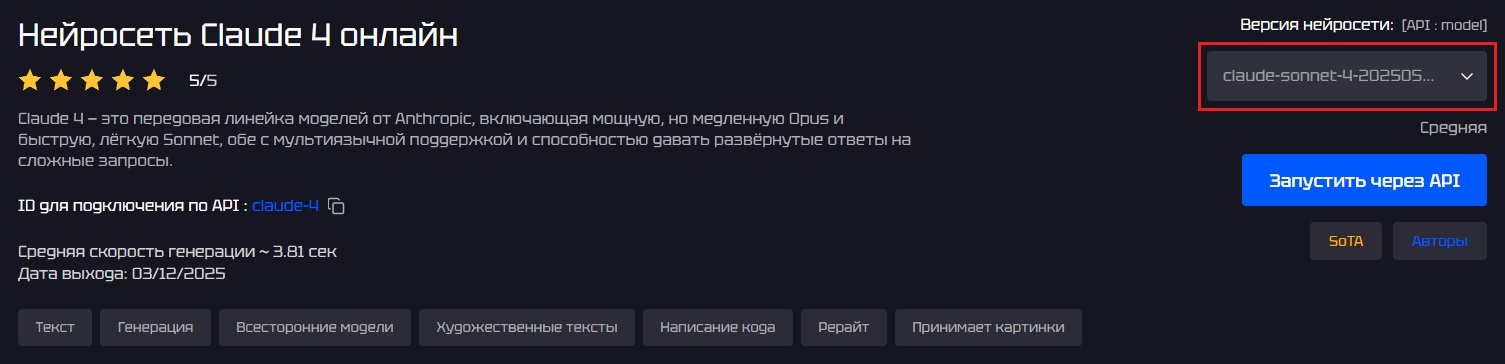
У некоторых нейросетей есть различные подверсии, например, у Claude есть Haiku, Sonnet или Opus, порой ещё и от разных дат. Чтобы выбрать конкретную, нужно выбрать нужное значение из поля model на странице нейросети
Примеры выбора модели в запросе
В зависимости от того, какую модель вы хотите использовать, значение поля model может быть либо общим идентификатором нейросети, либо точным названием подверсии.
Вариант 1. Использование общего идентификатора нейросети (slug)
В этом случае в параметре model передаётся идентификатор нейросети с сайта GenAPI (например, claude-4). Запрос будет обработан одной из доступных подверсий модели (обычно базовой или наиболее свежей).
Вариант 2. Использование конкретной подверсии
Если нейросеть имеет несколько подверсий (например, claude-opus-4-5, claude-sonnet-4-5), можно указать точное имя подверсии — ключ модели, который также отображается на сайте GenAPI.
Само тело запроса в нейросеть полностью соответствует стандартам OpenAI-формата, то есть то, как формируется тело запроса вы можете ознакомиться в документации OpenAI и прочих провайдеров. Тем не менее, здесь мы также пропишем основные возможности.
Общая структура запроса
Базовая структура запроса в OpenAI-формате:
Прикладывание изображений (vision)
Изображения передаются в массиве content через image_url (base64 или URL):
Можно передавать несколько изображений в одном запросе:
Прикладывание файлов (can_file)
Файлы передаются в массиве content через file:
Можно передавать несколько файлов в одном запросе:
Подробная информация доступна на странице Загрузка файлов в LLM.
Инструменты (tools)
Инструменты позволяют модели вызывать внешние функции. Опишите функции в параметре tools:
Модель вернёт вызов инструмента в поле tool_calls:
Потоковая генерация (stream)
Включите stream: true для получения ответа по частям:
Сервер отправляет данные в формате SSE:
Особенности мышления (reasoning)
Для моделей с поддержкой мышления (o1, o3) используйте параметр reasoning_effort (low, medium, high):
Влияние на токены
Токены мышления учитываются в общем потреблении. Чем выше reasoning_effort, тем больше токенов используется.
Финальный пример
Пример запроса, объединяющего все возможности OpenAI-формата: vision, tools, stream и reasoning:
В этом примере:
vision— анализ изображения в сообщенииtools— инструменты для получения данныхstream: true— потоковая передача ответаreasoning_effort— расширенное мышление модели
